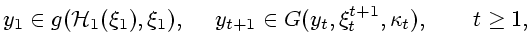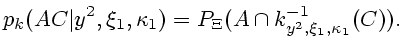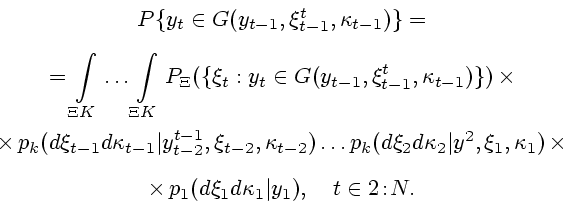Далее названием "множества информационной надежности" объединяем совокупности, определенные согласно (3.10) либо (4.1). Из содержания предыдущих пунктов и примеров ясно, что построить рекуррентные определяющие соотношения для рассматриваемых множеств в общем случае не всегда возможно. Поэтому введем некоторые предположения, которые гарантируют рекурсивность по крайней мере для случайных информационных множеств. Они пригодятся также и в дальнейшем для обобщения процедуры фильтрации.
Прежде чем обсудить данное предположение, напомним определение
универсально измеримых множеств. Для любой борелевской меры
![]() задается внешняя мера
задается внешняя мера
![]() и пополненная
и пополненная ![]() -алгебра
-алгебра
![]() . Тогда
. Тогда
![]() . Известно, что
. Известно, что
![]() , причем каждое из этих включений строгое, если
, причем каждое из этих включений строгое, если
![]() - несчетное множество, [14]. Здесь символом
- несчетное множество, [14]. Здесь символом ![]() обозначена
обозначена ![]() -алгебра, порожденная аналитическими
множествами [12]. В ограничениях (1.3) функции
-алгебра, порожденная аналитическими
множествами [12]. В ограничениях (1.3) функции ![]() выбирались полуаналитическими из-за того факта, что проекции
борелевских множеств не всегда будут борелевскими. В
предположении 5.1 мы вынуждены перейти к универсально
измеримым функциям, поскольку там фигурируют композиции
аналитических и борелевских функций. Отметим,что переход к
универсальной измеримости не затрудняет вычисление вероятностей
и интегралов по вероятностным мерам, [8].
выбирались полуаналитическими из-за того факта, что проекции
борелевских множеств не всегда будут борелевскими. В
предположении 5.1 мы вынуждены перейти к универсально
измеримым функциям, поскольку там фигурируют композиции
аналитических и борелевских функций. Отметим,что переход к
универсальной измеримости не затрудняет вычисление вероятностей
и интегралов по вероятностным мерам, [8].
Приступим к обсуждению предположения 5.1. Во-первых, оно позволяет описывать случайные информационные множества рекуррентным образом. Действительно, из равенства (3.5) в условиях предположения 5.1 вытекает соотношение
Во-вторых, следует отметить, что, хотя множества (3.2),
(3.4) и были ранее рекуррентно представлены через функции
![]() в общем случае, для этих функций затруднительно подобрать
подходящее функциональное пространство так, чтобы функции или
множества, описываемые ими, интерпретировались как точки в
искомом пространстве. Поэтому в предположении 5.1 и возникла
гипотеза о существовании пространства
в общем случае, для этих функций затруднительно подобрать
подходящее функциональное пространство так, чтобы функции или
множества, описываемые ими, интерпретировались как точки в
искомом пространстве. Поэтому в предположении 5.1 и возникла
гипотеза о существовании пространства ![]() . Ниже будут описаны
некоторые классы систем, для которых упомянутое предположение
выполняется.
. Ниже будут описаны
некоторые классы систем, для которых упомянутое предположение
выполняется.
В-третьих, предположение 5.1 по существу сводит ситуацию подсчета множеств информационной надежности к той, которая уже рассматривалась в примерах 3.9 и 4.4. Вычисления, которые при этом возникают, следует выполнять аналогично.
Рассмотрим их подробнее. Распределение пары
![]() при
заданных элементах
при
заданных элементах
![]() обозначим через
обозначим через
![]() . На прямоугольниках
. На прямоугольниках
![]() эта мера равна
эта мера равна
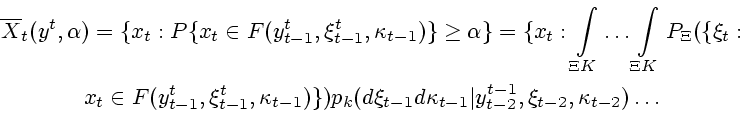
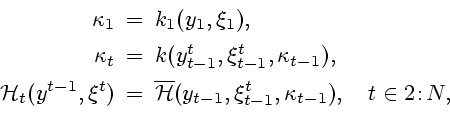
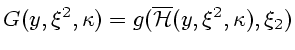
![\begin{displaymath}\begin{array}{c}X_t(y^t,\xi^t)=f(g^{-1}_{\xi_t}(y_t)\cap\over...
...^t_{t-1} ,\kappa _{t-1}),\\ [1ex]\quad t\in 2\!:\!N,\end{array}\end{displaymath}](img229.gif)