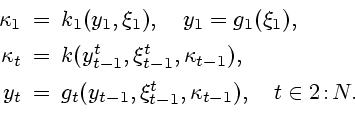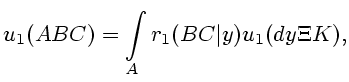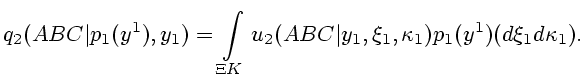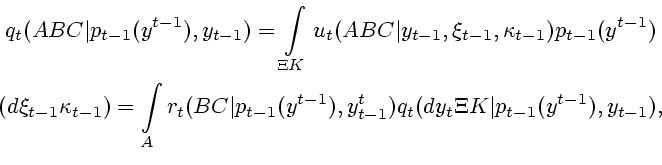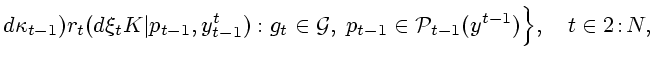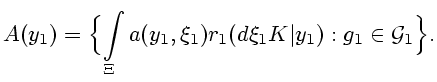Как уже отмечалось выше в пункте 3,
множества информационной надежности теряют свой смысл в чисто
случайных системах. Однако при предположении 5.1, благодаря
рекуррентному характеру случайных множеств, возможно обобщить
процедуру фильтрации нелинейных систем так, чтобы она подходила
и для чисто случайных, и для чисто детерминированных систем. В
данном пункте считаем предположение 5.1 выполненным.
Случайным состоянием нашей системы в момент ![]() является
множество
является
множество
![]() , согласно (5.3). Пусть
, согласно (5.3). Пусть
![]() - некоторая числовая
функция от информационного множества, обладающая свойством
универсальной измеримости. В частности, таковой будет функция
расстояния
- некоторая числовая
функция от информационного множества, обладающая свойством
универсальной измеримости. В частности, таковой будет функция
расстояния
![]() . Набор таких функций расстояния
при разных
. Набор таких функций расстояния
при разных ![]() позволяет восстановить замыкание множества. Можно
рассмотреть также и опорную функцию [1,11], но тогда будет
восстановлена только выпуклая и замкнутая оболочка множества.
Конечно, в последнем случае предполагается, что пространство
позволяет восстановить замыкание множества. Можно
рассмотреть также и опорную функцию [1,11], но тогда будет
восстановлена только выпуклая и замкнутая оболочка множества.
Конечно, в последнем случае предполагается, что пространство ![]() является линейным и локально выпуклым.
является линейным и локально выпуклым.
Итак, опишем вначале условные распределения для оценки неизвестной
функции
![]() ,
,
![]() .
Пусть
.
Пусть ![]() - это семейство селекторов многозначного
отображения (5.2), которое не пусто по предположению 5.1.
Аналогично,
- это семейство селекторов многозначного
отображения (5.2), которое не пусто по предположению 5.1.
Аналогично,
![]() - семейство универсально измеримых
селекторов на первом шаге. Для выбранной последовательности
селекторов
- семейство универсально измеримых
селекторов на первом шаге. Для выбранной последовательности
селекторов
![]()
![]()
![]() рассмотрим частично наблюдаемую
марковскую последовательность
рассмотрим частично наблюдаемую
марковскую последовательность
![]() , порождаемую
уравнениями
, порождаемую
уравнениями
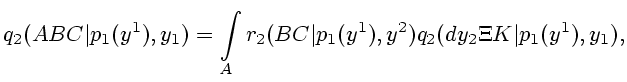
Таким образом, формулы (6.2)-(6.9) описывают процедуру
построения условных распределений для ненаблюдаемых величин в
системе (6.1). В силу неопределенности, которая выражается
здесь включениями (5.4), мы получаем семейства условных
распределений (6.9). Ясно, что процедура, представленная в
настоящем пункте, дает единообразное решение задачи фильтрации,
охватывающее крайние случаи пункта 2 при условиях предположения
5.1. Оценкой неизвестной функции
![]() будем считать множество
условных средних
будем считать множество
условных средних
![$\displaystyle A(y^t)=\{M[a(y^t_{t-1},\xi^t_{t-1},\kappa _{t-1})
\vert y^t]\}=
\...
...Xi}\int\limits_{\Xi
K}a(y^t_{t-1},\xi^t_{t-1},\kappa _{t-1})p_{t-1}(d\xi_{t-1}
$](img278.gif)