Оптимальные стратегии, разрешающие задачи 1.1 и 1.2 для
конфликтно-управляемых систем (1.1), будем строить в двух случаях,
выделенных в параграфе 2. В первом случае будем полагать,что множества
![]() и
и
![]() , описывающие динамику, задаются
равенствами
, описывающие динамику, задаются
равенствами
Во втором случае будем полагать,что динамика объектов задается равенствами
Будем предполагать, что функция ![]() , описывающая плату
игры, удовлетворяет следующему условию.
, описывающая плату
игры, удовлетворяет следующему условию.
Условие 3.1. Функция
![]() выпукла
и удовлетворяет глобальному условию
Коши-Липшица в
выпукла
и удовлетворяет глобальному условию
Коши-Липшица в ![]()
При выполнении условия 3.1 справедливо следующее равенство
[5, стр. 130]
![\begin{displaymath}
\sigma (x) = \max_{l \in L} {[l'x - \omega (l)]},
\end{displaymath}](img130.gif)
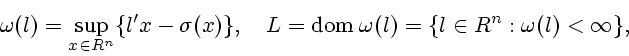
Введем в рассмотрение величину программного максимина [1,2]
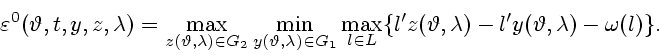
Будем предполагать, что игра регулярна [1-5], т.е. выполнено следующее условие.
Условие 3.2. Функция ![]() такова, что
существует такая достаточно малая
величина
такова, что
существует такая достаточно малая
величина
![]() , что максимум в правой части равенства
(3.5) достигается на единственном векторе
, что максимум в правой части равенства
(3.5) достигается на единственном векторе
![]() для всех позиций
для всех позиций ![]() , для которых
, для которых
![]() при
при
![]() .
Вектор-функция
.
Вектор-функция
![]() непрерывна по
непрерывна по ![]() и аналитична по переменным
и аналитична по переменным
![]() в области
в области
![]() .
.
Приведем примеры, когда выполнено условие 3.2. Для этого рассмотрим
игры сближения-уклонения, в которых плата равна евклидовой норме
вектора ![]() , т.е.
, т.е.
![]() .
Тогда
.
Тогда ![]() ,
,
![]() при
при ![]() ,
и программный максимин (3.5) определяется равенством
,
и программный максимин (3.5) определяется равенством
Условие 3.2 для программного максимина (3.6) будет выполнено,
если объекты однотипны, т.е. если
![]() и
и
![]() в первом случае и если
в первом случае и если
![]() и
и
![]() во втором случае. Требование
во втором случае. Требование
![]() существенно. В статье [13] приведен
пример, показывающий, что регулярность, имеющая место в случае линейных
однотипных объектов при
существенно. В статье [13] приведен
пример, показывающий, что регулярность, имеющая место в случае линейных
однотипных объектов при ![]() , отсутствует
за счет подходящего выбора нелинейных членов
при любых сколь угодно малых значениях
, отсутствует
за счет подходящего выбора нелинейных членов
при любых сколь угодно малых значениях
параметра ![]() .
.
Если условие 3.2 выполнено, то решение экстремальной задачи (3.5)
будем искать в виде ряда по степеням параметра ![]()
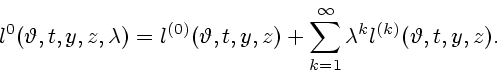
Введем в рассмотрение экстремальные стратегии [1-5].
О п р е д е л е н и е 3.1. Стратегии ![]() и
и ![]() называются экстремальными, если
в каждой позиции
называются экстремальными, если
в каждой позиции ![]() для которой при
для которой при
![]()
![]() ,
они определяются множествами
,
они определяются множествами
![]() состоящими из всех тех векторов
состоящими из всех тех векторов ![]() и
и ![]() , которые удовлетворяют
условиям максимума
, которые удовлетворяют
условиям максимума
![\begin{displaymath}
u'_e
{{\partial \rho_1 [l^0(\vartheta, t, y, z, \lambda), t,...
...vartheta, t, y, z,\lambda), t, y, \lambda] \over \partial y}},
\end{displaymath}](img164.gif)
![\begin{displaymath}
v'_e{{\partial \rho_2 [l^0(\vartheta, t, y, z,\lambda), t, z...
...\vartheta, t, y, z,\lambda), t, z, \lambda]\over \partial z}}.
\end{displaymath}](img165.gif)
В регулярном случае экстремальные стратегии ![]() и
и ![]() являются
допустимыми. Опираясь на методы работ [1,3,4,10] и
теорему 1, можно убедиться в справедливости следующего утверждения.
являются
допустимыми. Опираясь на методы работ [1,3,4,10] и
теорему 1, можно убедиться в справедливости следующего утверждения.
Теорема 3.1
Пусть динамика конфликтно управляемых систем
описывается уравнениями ![]() ,
, ![]() ,
, ![]() или
или ![]() ,
, ![]() ,
, ![]() ,
удовлетворяющими условиям
,
удовлетворяющими условиям ![]() или
или ![]() , и пусть плата игры
удовлетворяет условию
, и пусть плата игры
удовлетворяет условию ![]() . Тогда в регулярном случае
экстремальные стратегии
. Тогда в регулярном случае
экстремальные стратегии ![]() и
и ![]() разрешают задачи
разрешают задачи ![]() и
и
![]() соответственно. Пара стратегий
соответственно. Пара стратегий ![]() составляет
седловую точку игры, причем цена игры
составляет
седловую точку игры, причем цена игры
![]() совпадает с программным максимином, т.е.
совпадает с программным максимином, т.е.
![]() ,
непрерывна по
,
непрерывна по ![]() , аналитична по
, аналитична по
![]() в области
в области
![]() и удовлетворяет
уравнению Гамильтона - Якоби при условии
и удовлетворяет
уравнению Гамильтона - Якоби при условии
![]()
![\begin{displaymath}
\varepsilon^0(\vartheta, t, y, z, \lambda) = \max_{l \in L} ...
...\lambda] -\rho_1 [l, \vartheta, t, y, \lambda] -
\omega (l)\}.
\end{displaymath}](img137.gif)
![\begin{displaymath}
\varepsilon^0 (\vartheta, t, y, z, \lambda)=\max_{l \in S} \...
...heta, t, z, \lambda] -
\rho_1 [l, \vartheta, t, y, \lambda]\}.
\end{displaymath}](img148.gif)