Рассмотрим управляемую систему
Будем полагать, что многозначное отображение
![]() удовлетворяет одному из следующих условий.
удовлетворяет одному из следующих условий.
Условие 2.1.
(а) Множество
![]() имеет вид
имеет вид
(б) Матрица ![]() определенно положительна и
непрерывна по
определенно положительна и
непрерывна по ![]()
(в) Функция
![]() непрерывна по
непрерывна по ![]() и аналитична по
всем остальным переменным.
и аналитична по
всем остальным переменным.
Такие ситуации типичны, когда совпадают размерности управляющей силы и фазовых координат, или, наряду с ограничениями на управляющие силы, имеются также ограничения на скорости изменения всех фазовых координат управляемого процесса.
Условие 2.2.
(а) Множество
![]() имеет вид
имеет вид
(б) Матрицы
![]() и
и
![]() непрерывны по
непрерывны по ![]() причем
причем ![]() .
.
(в) Пусть ![]() - фундаментальная матрица решений линейной
однородной системы
- фундаментальная матрица решений линейной
однородной системы
![]() . Каков бы ни был единичный вектор
. Каков бы ни был единичный вектор
![]() , вектор-функция
, вектор-функция
(г) Функция
![]() непрерывна по
непрерывна по ![]() и аналитична
по всем остальным переменным.
и аналитична
по всем остальным переменным.
При выполнении условия 2.1 (или 2.2) дифференциальное включение
(2.1), (2.2) (или (2.1), (2.3)) для любой
начальной позиции ![]() имеет при достаточно малых значениях
параметра
имеет при достаточно малых значениях
параметра ![]() множество
множество
![]() решений
решений
![]() , определенных на
любом заданном отрезке времени
, определенных на
любом заданном отрезке времени
![]()
Сечение множества
![]() при
при ![]() будем называть
областью достижимости системы (2.1) из состояния
будем называть
областью достижимости системы (2.1) из состояния ![]() к моменту времени
к моменту времени ![]() и обозначать символом
и обозначать символом
![]() При условии 2.1 (или 2.2) и малых
значениях
При условии 2.1 (или 2.2) и малых
значениях ![]() множество
множество
![]() является строго выпуклым, замкнутым и ограниченным.
Для построения решений
задач 1.1 и 1.2 необходимо знать опорную функцию
является строго выпуклым, замкнутым и ограниченным.
Для построения решений
задач 1.1 и 1.2 необходимо знать опорную функцию
![]() области достижимости
области достижимости
![]() при
при
В рассматриваемых ситуациях, описываемых условиями 2.1 и 2.2, для построения опорной функции удобно пользоваться методом динамического программирования.
Теорема 2.1. Пусть выполнено условие ![]() (или
(или ![]() ), тогда опорная
), тогда опорная
функция
![]() области достижимости
области достижимости
![]() является непрерывной функцией
времени и при каждом
является непрерывной функцией
времени и при каждом ![]() аналитической функцией переменных
аналитической функцией переменных ![]() в области
в области
![]() , где
, где ![]() -
произвольное ограниченное множество в
-
произвольное ограниченное множество в ![]() и
и ![]() - некоторая
малая окрестность точки
- некоторая
малая окрестность точки ![]() .
.
Д о к а з а т е л ь с т в о. Проверим справедливость утверждения теоремы в случае, когда
выполнено условие 2.1. При условии 2.2 доказательство проводится
аналогично с несущественными изменениями.
Опорная функция
![]() является [10]
решением задачи Коши
является [10]
решением задачи Коши
![\begin{displaymath}
\rho^{(0)} [l, \vartheta, t, x]=l'x+
\zeta \int\limits_t^\vartheta(l'[R^{(1)}(\tau)]^{-1}l)^{1/2}d\tau.
\end{displaymath}](img97.gif)
![\begin{displaymath}
\psi ={\partial \rho [l, \vartheta, t, x, \lambda] \over \partial x},
\end{displaymath}](img99.gif)
![\begin{displaymath}
\lambda \frac{\partial \varkappa}{\partial t} -
\zeta (l'[R^...
...\frac{\partial \varkappa }
{\partial x }\bigg )\bigg ]^{1/2} +
\end{displaymath}](img104.gif)
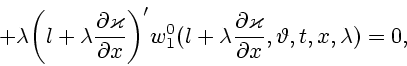
Квадратичная форма
![]() при всех
при всех ![]() и
и
![]() , поэтому для произвольной ограниченной области
, поэтому для произвольной ограниченной области
![]() можно указать достаточно малую величину
можно указать достаточно малую величину
![]() такую, что функция
такую, что функция
![]() будет аналитической по
будет аналитической по
![]() и
и ![]() при достаточно малых значениях
при достаточно малых значениях
![]() ,
что и доказывает справедливость теоремы.
,
что и доказывает справедливость теоремы.
Таким образом, при
![]() опорную функцию можно искать в виде сходящегося ряда
опорную функцию можно искать в виде сходящегося ряда
![\begin{displaymath}
\rho [l, \vartheta, t, x, \lambda] = \rho^{(0)} [l, \varthet...
...m_{k=1}^\infty \lambda^k \varkappa^{(k)} [l, \vartheta, t, x].
\end{displaymath}](img114.gif)
Отметим, что в случае, когда размерность управляющей силы меньше,
чем размерность фазового вектора, теорема 2.1, вообще говоря, неверна.
В статье [12] приведены примеры, когда функция
![]() недифференцируема по
недифференцируема по ![]() .
В таких ситуациях условия 2.2(б) и 2.2(в) оказываются существенными.
Существенными являются и требования 2.1(а), 2.2(б). Если опорная
гиперплоскость имеет касание с границей области управления более высокого
порядка, чем первый, то опорная функция области управления
недифференцируема по
.
В таких ситуациях условия 2.2(б) и 2.2(в) оказываются существенными.
Существенными являются и требования 2.1(а), 2.2(б). Если опорная
гиперплоскость имеет касание с границей области управления более высокого
порядка, чем первый, то опорная функция области управления
недифференцируема по ![]() и, следовательно, теорема 2.1 также, вообще говоря,
неверна.
и, следовательно, теорема 2.1 также, вообще говоря,
неверна.
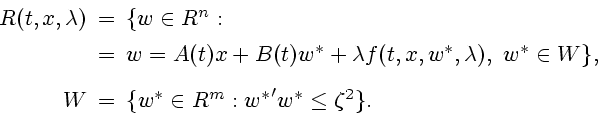
![\begin{displaymath}
\frac{\partial \rho }{\partial t}+\max_{w \in R(t,x,\lambda)...
...x}=0, \quad
\rho [l, \vartheta, x, \lambda]=l'x,\quad l \in S.
\end{displaymath}](img96.gif)