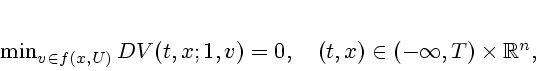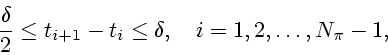The construction of a discontinuous near optimal feedback control law universal on a prescribed set first appeared in Krasovskii [31] and was elaborated upon in [32] and [33]; see also Krasovskii and Subbotin [34], [35]. Unlike these motivating seminal works, we take a proximal analytic approach in our constructions, in line with the results of the previous section on stabilizability.
Suppose that
![]() is a compact set which is weakly invariant (or in alternate terminology, viable or
holdable);
that is, for any
is a compact set which is weakly invariant (or in alternate terminology, viable or
holdable);
that is, for any
![]() there exists a control
there exists a control ![]() such that
such that
![]() for
all
for
all ![]() . Let
. Let
![]() be continuous,
and let
be continuous,
and let
![]() be fixed. For an initial phase
be fixed. For an initial phase
![]() ,
consider the following fixed time endpoint cost optimal control problem
,
consider the following fixed time endpoint cost optimal control problem
![]() with state constraint
with state constraint ![]() :
:
minimize ![]()
subject to
![]() .
.
Let us now add the condition
Then, by standard ``sequential compactness of trajectories'' arguments, the following facts are readily verified:
As before, by a feedback we simply mean any selection of ![]() of the form
of the form
![]() . We will
commence to sketch the method in Clarke, Rifford, and Stern
[18] for producing a feedback
. We will
commence to sketch the method in Clarke, Rifford, and Stern
[18] for producing a feedback ![]() which generates a
near optimal trajectory which nearly satisfies the state
constraint, with respect to the
which generates a
near optimal trajectory which nearly satisfies the state
constraint, with respect to the ![]() -trajectory discretized
solution concept; complete details can be found in that reference.
This feedback will be operative universally for all initial phases
in a specified bounded subset of
-trajectory discretized
solution concept; complete details can be found in that reference.
This feedback will be operative universally for all initial phases
in a specified bounded subset of
![]() , and it is
robust with respect to measurement and external errors. The main
idea is to adapt the arguments employed in [12] in
proving the stabilizability result given by Theorem 2.4
above to the present problem, with the value function taking over
the role played by the CLF
, and it is
robust with respect to measurement and external errors. The main
idea is to adapt the arguments employed in [12] in
proving the stabilizability result given by Theorem 2.4
above to the present problem, with the value function taking over
the role played by the CLF ![]() in our prior feedback
stabilizability considerations. Note well, however, that a
serious technical difficulty must be overcome in achieving this:
The method in Theorem 2.4 required local Lipschitzness
of the CLF
in our prior feedback
stabilizability considerations. Note well, however, that a
serious technical difficulty must be overcome in achieving this:
The method in Theorem 2.4 required local Lipschitzness
of the CLF ![]() (in obtaining (2.11)), but the value function
in the present problem may not even be continuous, as was pointed
out in Remark 3.1.
(in obtaining (2.11)), but the value function
in the present problem may not even be continuous, as was pointed
out in Remark 3.1.
We require the following notation for ``enlarged'' dynamics.
For
![]() , we denote
, we denote
Our result is the following.
Hence, it is asserted that the feedback ![]() produces a
produces a ![]() -trajectory
for the enlarged dynamics (3.1), which is
-trajectory
for the enlarged dynamics (3.1), which is ![]() -optimal and which remains
-optimal and which remains ![]() -near
-near ![]() in
a manner which is robust and effective universally for any initial phase in
the generalized rectangle
in
a manner which is robust and effective universally for any initial phase in
the generalized rectangle
![]() .
.
Without loss of generality, we shall for notational ease assume ![]() and
take
and
take ![]() in the statement of Theorem 3.2.
in the statement of Theorem 3.2.
Define a lower semicontinuous extended real valued function
![]() as
as
![\begin{displaymath}
% latex2html id marker 555\widetilde V(t,x) := \left \{
\b...
...[0,T]\times S, \\ \infty & {\rm
otherwise}
\end{array}\right .
\end{displaymath}](img252.gif) |
(3.8) |
(1.1) with
![]() , satisfies
, satisfies
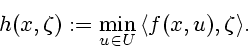
Given ![]() , we now define the lower semicontinuous extended
real valued function
, we now define the lower semicontinuous extended
real valued function
![]() as
as
![\begin{displaymath}
% latex2html id marker 1902\widetilde{V}^{\beta }(t,x):=\w...
... [0,T]\times S, \\ \infty &
{\rm otherwise}
\end{array}\right.
\end{displaymath}](img263.gif)
For a parameter value ![]() , we denote by
, we denote by
![]() the quadratic inf-convolution of
the quadratic inf-convolution of
![]() ; that is
; that is
The idea of using the quadratic inf-convolution in order to construct near optimal strategies goes back to Subbotin and his coworkers, where it was employed in a differential games context; see, e.g., Subbotin [51].
Since ![]() is compact in the present case, we have
is compact in the present case, we have
Denote
![\begin{displaymath}
m_{u} := \max_{(t,x)\in [0,T]\times S}\{\ell(x)+\beta (T-t)\} =
\max_{x\in S} \ell(x) + \beta T
\end{displaymath}](img272.gif)
![\begin{displaymath}
m_{\ell} := \min_{(t,x)\in [0,T]\times S}\widetilde V^\beta(...
...
\min_{(t,x)\in [0,T]\times S}\widetilde V_\lambda^\beta(t,x).
\end{displaymath}](img273.gif)
These extrema are attained due to the compactness of ![]() , continuity of
, continuity of ![]() , lower semicontinuity of
, lower semicontinuity of
![]() , and continuity of
, and continuity of
![]() . The fact that the second equality involving
. The fact that the second equality involving ![]() holds for any
holds for any ![]() is evident from (3.14). Note also
that
is evident from (3.14). Note also
that
Suppose
![]() at some
at some
![]() . Basic proximal
analytic facts about the quadratic inf-convolution (see Clarke,
Ledyaev, and Wolenski [17] as well as the exposition in
[20]) are that
. Basic proximal
analytic facts about the quadratic inf-convolution (see Clarke,
Ledyaev, and Wolenski [17] as well as the exposition in
[20]) are that
In addition, we will require some elementary lemmas.
We now fix
![]() ; subsequently it is required that
; subsequently it is required that ![]() be taken sufficiently small. The next lemma follows easily from the previous
one and (3.11).
be taken sufficiently small. The next lemma follows easily from the previous
one and (3.11).
We now introduce notation for the sublevel sets of
![]() and
and
![]()
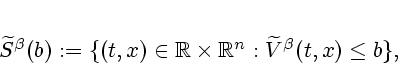
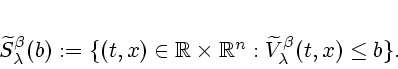
We shall also require the following lemma, which asserts how the
sublevel sets of
![]() are approximated by those of
its quadratic inf-convolution. (We denote the Hausdorff metric by
``haus''.)
are approximated by those of
its quadratic inf-convolution. (We denote the Hausdorff metric by
``haus''.)
Now fix ![]() ; we will not require the smallness of this parameter. It is
easy to see that for any
; we will not require the smallness of this parameter. It is
easy to see that for any ![]() and
and ![]() one has
one has
This puts us in a position to adapt the general technique used in proving
Theorem 2.4 to the function
![]() with
with ![]() chosen as above.
For the given
chosen as above.
For the given ![]() in the statement of Theorem 3.2, the
parameters
in the statement of Theorem 3.2, the
parameters
![]() and
and ![]() are taken sufficiently small,
are taken sufficiently small, ![]() near
near ![]() , and
, and ![]() near
near ![]() , in such a
way that further estimates lead to the required conclusion. The
idea of the proof is to use (3.21) and (3.22) in
order to show that
, in such a
way that further estimates lead to the required conclusion. The
idea of the proof is to use (3.21) and (3.22) in
order to show that ![]() achieves appropriate nonincrease while
never leaving the set
achieves appropriate nonincrease while
never leaving the set
![]() ; a shell based construction is
employed, as described in connection with Theorem 2.4.
; a shell based construction is
employed, as described in connection with Theorem 2.4.
Berkovitz [6] provided a method of universal feedback
construction for optimal control, quite different from those mentioned
above, but one which also relies upon a nonsmooth Hamilton-Jacobi approach.
In the context of the present article, Berkovitz's approach can be described
as follows. Since the value function ![]() of the problem is known to
satisfy the generalized Hamilton-Jacobi inequality
of the problem is known to
satisfy the generalized Hamilton-Jacobi inequality
An approach to feedback construction related to [6] and [53] was undertaken by Cannarsa and Frankowska in [8]; in
that work, additional conditions on the cost functional and dynamics were
given which provide the requisite regularity in Berkovitz's original
procedure, namely, smoothness of ![]() .
.
In Rowland and Vinter [45], a modification of
Berkovitz's method is given which overcomes the lack of regularity
of ![]() without imposing extra conditions. Rowland and Vinter
provided a discretization procedure (but not a feedback law) which
in the limit produces an optimal trajectory for any initial phase.
without imposing extra conditions. Rowland and Vinter
provided a discretization procedure (but not a feedback law) which
in the limit produces an optimal trajectory for any initial phase.
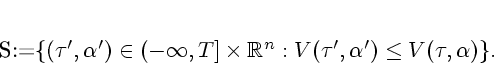
Let us now posit the following additional geometric assumptions on the state
constraint set ![]() :
:
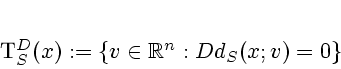
In Clarke, Rifford, and Stern [18], the following result is proven by means of a state constrained tracking lemma.
We denote
![]() , and for
, and for ![]() ,
we denote the r-inner approximation of
,
we denote the r-inner approximation of ![]() by
by
In other words, under the strengthened hypotheses on ![]() , for a
given tolerance
, for a
given tolerance
![]() , if one considers any
sufficiently tight inner approximation
, if one considers any
sufficiently tight inner approximation ![]() of
of ![]() , there exists
a robust feedback
, there exists
a robust feedback ![]() effective universally for initial phases
in
effective universally for initial phases
in
![]() , such that for each such initial phase, the
, such that for each such initial phase, the
![]() -trajectory produced (for the original, i.e. not enlarged dynamics)
is
-trajectory produced (for the original, i.e. not enlarged dynamics)
is ![]() -optimal
and remains in
-optimal
and remains in ![]() . This is in contrast to Theorem 3.2, where the
. This is in contrast to Theorem 3.2, where the ![]() -trajectory only remains
-trajectory only remains ![]() -near
-near ![]() under enlarged dynamics.
under enlarged dynamics.
Further results,including a Hamilton-Jacobi characterization of the state constrained value, are to appear in [18].
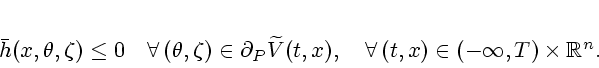
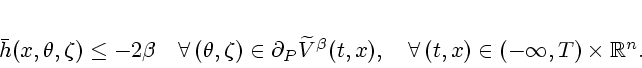
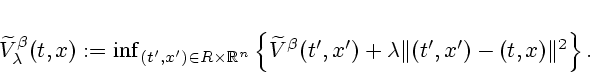
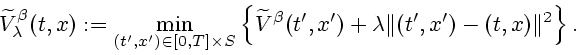
![\begin{displaymath}
\sup_{(t,x)\in [0,T]\times S}\widetilde V^\beta_\lambda(t,x)...
...sup_{(t,x)\in [0,T]\times S}\widetilde V^\beta(t,x) \leq m_u.
\end{displaymath}](img277.gif)
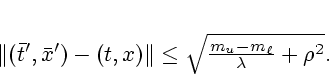
![\begin{displaymath}
% latex2html id marker 690{\rm haus}\left[ \widetilde{S}_{...
...^{\beta
}(c)\right] \leq \sqrt{\frac{c-m_{\ell }}{\lambda }}.
\end{displaymath}](img296.gif)
![\begin{displaymath}
% latex2html id marker 710[0,T]\times S \subset {\rm int} \{\widetilde S^\beta_\lambda(m_u+\eta)\}.
\end{displaymath}](img299.gif)
![\begin{displaymath}
% latex2html id marker 715[0,T]\times S \subset {\rm int} ...
...epsilon^{\prime})B_{n+1}
=: Q(T,\hat T,\varepsilon^{\prime}).
\end{displaymath}](img301.gif)