Классическая постановка задачи выбора структуры портфеля рисковых
инвестиций предполагает наличие ![]() рисковых вложений (ценных
бумаг) с заданными доходностями
рисковых вложений (ценных
бумаг) с заданными доходностями
![]() , которые
трактуются как случайные величины. Их ожидаемые значения и матрицу
ковариации обозначим через
, которые
трактуются как случайные величины. Их ожидаемые значения и матрицу
ковариации обозначим через ![]() и
и
![]() соответственно.
соответственно.
Предполагается также, что имеется возможность безрисковых
вложений; соответствующую доходность обозначим ![]() . Портфель
определяется вектором
. Портфель
определяется вектором
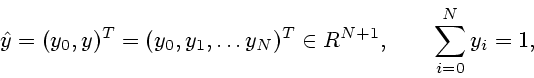
Ожидаемая доходность портфеля определяется соотношением
![]() , где
, где
![]() , а среднеквадратичное
отклонение
, а среднеквадратичное
отклонение
![]() интерпретируется как
соответствующий риск. Таким образом, каждому портфелю
интерпретируется как
соответствующий риск. Таким образом, каждому портфелю ![]() на
плоскости
на
плоскости ![]() (риск-доходность) соответствует
определенная точка. Портфель
(риск-доходность) соответствует
определенная точка. Портфель
![]() называется
эффективным или недоминируемым, если не существует портфеля
называется
эффективным или недоминируемым, если не существует портфеля ![]() ,
для которого
,
для которого
![]() и
и
![]() , где по крайней мере одно из неравенств
строгое.
, где по крайней мере одно из неравенств
строгое.
Задача построения множества эффективных портфелей из чисто
рисковых активов была поставлена и решена Г.Марковицем [2].
Это решение хорошо известно и (при условии положительной
определенности матрицы ![]() и наличия у вектора
и наличия у вектора ![]() различных
компонент) легко может быть получено методом множителей Лагранжа.
Названные условия предполагаются далее выполненными.
Геометрически на плоскости
различных
компонент) легко может быть получено методом множителей Лагранжа.
Названные условия предполагаются далее выполненными.
Геометрически на плоскости ![]() недоминируемым портфелям
соответствует ветвь гиперболы, уравнение которой выписывается
явным образом.
недоминируемым портфелям
соответствует ветвь гиперболы, уравнение которой выписывается
явным образом.
Наличие безрискового актива только упрощает вычисления при
построении эффективного множества. Соотношение, связывающее риск и
ожидаемую доходность недоминируемых портфелей, здесь линейно:
![]() ,
,
Вектор рисковой части эффективного портфеля, соответствующего
заданной доходности
![]() или заданному уровню
риска
или заданному уровню
риска ![]() , может быть выражен следующим образом:
, может быть выражен следующим образом:
Последние соотношения отражают, в частности, то обстоятельство, что структура рисковой части эффективных портфелей одинакова. Названный факт лежит в основе модели ценообразования САРМ: если все инвесторы руководствуются критериями риск-доходность в указанном выше смысле, то каждый из них формирует свой портфель, распределяя вложения в рисковые активы в одних и тех же пропорциях. Оптимальным в данной модели является распределение средств между двумя портфелями - безрисковым активом и рисковым портфелем фиксированной структуры. Данный результат иногда называют теоремой о двух фондах (two-fund theorem). Из этого, в свою очередь, выводится, что названная структура должна совпадать со структурой существующего реального рыночного портфеля, что дает возможность определить равновесные цены и различные характеристики реальных финансовых инструментов.
Фигурирующие в приведенных построениях доходности в простейшем
случае представимы в виде
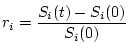 , где
, где ![]() - цена
актива
- цена
актива ![]() в момент времени
в момент времени ![]() , отрезок
, отрезок ![]() - фиксирован.
Если на допустимые значения долей капитала
- фиксирован.
Если на допустимые значения долей капитала ![]() наложены
дополнительные ограничения, например
наложены
дополнительные ограничения, например ![]() , то для
нахождения множества эффективных портфелей могут быть использованы
как стандартные методы математического программирования, так и
специальные алгоритмы [16].
, то для
нахождения множества эффективных портфелей могут быть использованы
как стандартные методы математического программирования, так и
специальные алгоритмы [16].
Другой подход к выбору оптимальных решений использует
доверительные интервалы для случайного значения доходности
портфеля
![]() . В качестве оптимального
выбирается вектор
. В качестве оптимального
выбирается вектор ![]() , решающий задачу максимизации вероятности
получения заранее заданного значения доходности
, решающий задачу максимизации вероятности
получения заранее заданного значения доходности ![]() :
:
Приведем некоторые результаты, относящиеся к задаче с непрерывным
пересмотром долей портфеля в упрощенной постановке (без учета
комиссии, спреда, налогов и др.). Общепринятой моделью изменения
цен акций в этом случае является модель геометрического
броуновского движения:
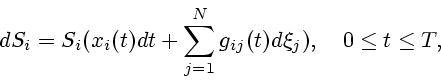
Динамика капитала, соответствующего ![]() -му активу описывается в
этом случае также стохастическим дифференциальным уравнением:
-му активу описывается в
этом случае также стохастическим дифференциальным уравнением:
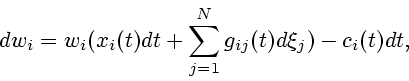
Уравнение изменения всего капитала
![]() имеет вид
имеет вид
Класс допустимых управлений определяется таким образом, чтобы
обеспечить существование решения уравнения (1.5) и
корректность определения функционала качества, а также
дополнительные свойства, отражающие содержательную постановку
задачи (например, неотрицательность текущего значения капитала
![]() и др.)
и др.)
Оптимальные по критерию (1.6) управления ![]() ,
выбираемые в подходящем классе допустимых управлений, обладают тем
свойством, что при всех
,
выбираемые в подходящем классе допустимых управлений, обладают тем
свойством, что при всех ![]() принадлежат множеству эффективных
портфелей
принадлежат множеству эффективных
портфелей
![]() , где
, где
Отсюда следует, в частности, что в динамической задаче, как и в
статическом случае справедлива двухфондовая теорема [6].
Конкретный вид управлений ![]() зависит от выбираемых функций
полезности
зависит от выбираемых функций
полезности ![]() и
и ![]() [20].
[20].
В заключение данного раздела установим утверждение, относящееся к задаче квантильной оптимизации инвестиционного портфеля.
Будем рассматривать случай, когда целью управления
является максимизация случайного значения капитала ![]() ,
получаемого с заданной вероятностью, а потребление на интервале
,
получаемого с заданной вероятностью, а потребление на интервале
![]() отсутствует. Класс допустимых управлений
отсутствует. Класс допустимых управлений ![]() ограничим детерминированными непрерывными функциями времени
ограничим детерминированными непрерывными функциями времени
![]() (программные управления). Динамика изменения капитала,
отвечающая фиксированному управлению
(программные управления). Динамика изменения капитала,
отвечающая фиксированному управлению ![]() , в этом случае
описывается уравнением:
, в этом случае
описывается уравнением:
Решение стохастического дифференциального уравнения
(1.8), отвечающее начальному условию ![]() ,
понимается в стандартном смысле (см., например, [21]).
Рассматриваемая задача максимизации гарантированной с заданной
вероятностью
,
понимается в стандартном смысле (см., например, [21]).
Рассматриваемая задача максимизации гарантированной с заданной
вероятностью ![]()
![]() доходности портфеля
имеет вид
доходности портфеля
имеет вид
![\begin{displaymath}
y_\alpha(t)= \left[
1-\frac{k_\alpha}{\sqrt{D^*(T)}} \right]_+ y^*(t)
\end{displaymath}](img74.gif)
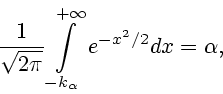
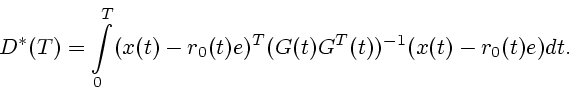
Доказательство теоремы базируется на следующих леммах.
Действительно, для любой непрерывной детерминированной функции
![]() величина
величина
![]() распределена по логнормальному
закону и, следовательно, для
распределена по логнормальному
закону и, следовательно, для
![]() имеем
имеем
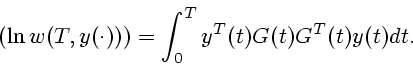
Д о к а з а т е л ь с т в о. В силу Леммы 1 каждое решение
![]() задачи (1.9) есть одновременно и решение задачи
(1.10). Отсюда следует, что найдутся числа
задачи (1.9) есть одновременно и решение задачи
(1.10). Отсюда следует, что найдутся числа ![]() и
и
![]() , не равные одновременно нулю, для которых
, не равные одновременно нулю, для которых
![]() максимизирует свертку критериев
максимизирует свертку критериев
![]() . Предполагая, что
. Предполагая, что ![]() и обозначая
и обозначая ![]() , с учетом (1.12)
находим явное представление для решения
, с учетом (1.12)
находим явное представление для решения
![]() , где
, где
![]() . При
. При
![]() решение имеет требуемый вид со значением
решение имеет требуемый вид со значением ![]() .
.
Из доказанных лемм следует, что решение задачи (1.9)
можно искать в классе управлений вида
![]() . Подставляя
. Подставляя
![]() в функционал (1.10), приходим к
задаче максимизации функции одного числового параметра
в функционал (1.10), приходим к
задаче максимизации функции одного числового параметра ![]() ,
которая после несложных преобразований приводится к виду
,
которая после несложных преобразований приводится к виду
![\begin{displaymath}\frac{1}{2}\lambda^2 - a\lambda \to \min\limits_{\lambda\in
[0,1]}, \end{displaymath}](img106.gif)
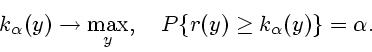
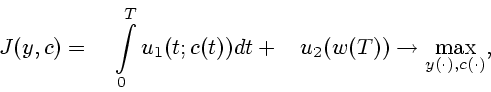
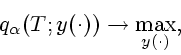
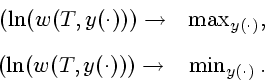
![\begin{displaymath}
{}= \int^T_0[r_0(t) + (x(t)-r_0(t)e)^Ty(t)
-\frac{1}{2} y^T(t)G(t) G^T(t)y(t)]dt+ \ln w_0,
\end{displaymath}](img86.gif)