Рассмотрим теперь вспомогательные
антагонистические позиционные дифференциальные игры
![]() и
и
![]() Динамика обеих игр описывается уравнением
(1.1). В игре
Динамика обеих игр описывается уравнением
(1.1). В игре
![]() игрок
игрок ![]() максимизирует
функционал выигрыша
максимизирует
функционал выигрыша
![]() (1.2) а игрок
(1.2) а игрок
![]() противодействует ему.
противодействует ему.
Пусть выполнено следующее предположение.
5![]() . Функция
. Функция
![]() (1.1) удовлетворяет условию
(1.1) удовлетворяет условию
Тогда из [2] следует, что обе игры
![]() и
и
![]() имеют универсальные седловые точки
имеют универсальные седловые точки
Свойство стратегий (2.2) быть универсальными означает, что
они являются оптимальными не только для фиксированной начальной
позиции
![]() , но и для любой позиции
, но и для любой позиции
![]() , рассматриваемой в качестве начальной.
, рассматриваемой в качестве начальной.
Теперь сформулируем следующие задачи.
Пусть кусочно-непрерывные функции
![]() и
и
![]() порождают траекторию
порождают траекторию
![]() системы (1.1).
Рассмотрим стратегии 1-го и 2-го игроков
системы (1.1).
Рассмотрим стратегии 1-го и 2-го игроков
6![]() . Вектограмма системы (1.1)
. Вектограмма системы (1.1)
Это предположение
![]() гарантирует, что множество
достижимости системы (1.1), порожденное измеримыми
управлениями, замкнуто относительно равномерной сходимости.
гарантирует, что множество
достижимости системы (1.1), порожденное измеримыми
управлениями, замкнуто относительно равномерной сходимости.
Справедливы следующие результаты [3].
Таким образом, теоремы 2.1 и 2.2 устанавливают соответствия между
множествами решений задач 2.1, 2.2, 2.3.i, 2.4.i и множествами
![]() -,
-, ![]() -,
-, ![]() -, и
-, и ![]() -решений. Эти теоремы
определяют структуру решений игры. Теоремы существования
-решений. Эти теоремы
определяют структуру решений игры. Теоремы существования ![]() -,
-,
![]() -,
-, ![]() -, и
-, и ![]() -решений являются следствиями
теорем 2.1 и 2.2.
-решений являются следствиями
теорем 2.1 и 2.2.
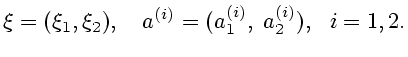
Обозначая
![]() и производя замену переменных
и производя замену переменных
![]() ,
,
![]() ,
,
![]() ,
,
![]() , получим систему, два первых уравнения которой
будут
, получим систему, два первых уравнения которой
будут
Далее, (2.9) может быть переписано так
Так как функционал выигрыша (2.11) зависит только от
переменных ![]() и
и ![]() , а правая часть (2.10) не
зависит от других переменных, можно заключить, что достаточно
рассматривать только укороченную систему (2.10) с
функционалами выигрыша (2.11).
, а правая часть (2.10) не
зависит от других переменных, можно заключить, что достаточно
рассматривать только укороченную систему (2.10) с
функционалами выигрыша (2.11).
Тогда начальные условия для системы (2.10) задаются формулами
![$\displaystyle x_{i}[t_{0}]=x_{0i}=\xi_{0i}-(\theta-t_{0})\dot{\xi}_{0i},\ \ \ i=1,2$](img167.gif)
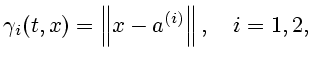
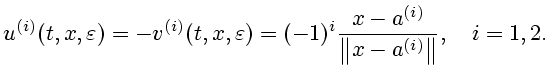
Пусть заданы следующие начальные условия и значения параметров:
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
, ![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() . Тогда имеем
. Тогда имеем
![]() .
.
Используя теоремы 2.1 и 2.2, можно построить решения игры. Мы
опишем построенные множества ![]() -решений,
-решений, ![]() -решений,
-решений, ![]() -решений и
-решений и ![]() -решений через множества концов
траекторий, порожденных этими решениями. На рис. 1 круг
радиуса 4 с центром в начальной точке
-решений через множества концов
траекторий, порожденных этими решениями. На рис. 1 круг
радиуса 4 с центром в начальной точке
![]() представляет
собою множество достижимости системы (2.10) в момент
представляет
собою множество достижимости системы (2.10) в момент
![]() . Кривая
. Кривая
![]() ограничивает множество
концов траекторий, порожденных
ограничивает множество
концов траекторий, порожденных ![]() -решениями. Кривая
-решениями. Кривая
![]() представляет собою множество концов
траекторий для
представляет собою множество концов
траекторий для ![]() -решений. Наконец, точка
-решений. Наконец, точка ![]() является
единственной конечной точкой, порожденной
является
единственной конечной точкой, порожденной ![]() -решением и
-решением и
![]() -решением одновременно. Аналогично, точка
-решением одновременно. Аналогично, точка ![]() является
единственной конечной точкой, порожденной
является
единственной конечной точкой, порожденной ![]() -решением и
-решением и
![]() -решением одновременно. Заметим, что кривые
-решением одновременно. Заметим, что кривые ![]() и
и
![]() суть дуги окружностей с центрами в точках
суть дуги окружностей с центрами в точках ![]() и
и
![]() соответственно.
соответственно.
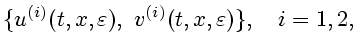
![\begin{displaymath}\begin{array}[c]{c} u^{0}(t,x,\varepsilon)=\left\{ \begin{arr...
...\Vert \geq\varepsilon\varphi(t) \end{array} \right. \end{array}\end{displaymath}](img116.gif)
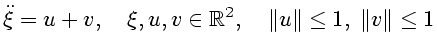
![$\displaystyle \xi\lbrack t_{0}]=\xi_{0},\;\;\dot{\xi}\lbrack t_{0}]=\xi_{0}$](img148.gif)
![$\displaystyle \sigma_{i}(\xi\lbrack\theta])=-\left\Vert \xi\lbrack\theta]-a^{(i)}\right\Vert ,$](img154.gif)
![\begin{displaymath}\begin{array}[c]{c} \overset{\cdot}{x_{1}}=(\theta-t)(u_{1}+v...
...1ex] \overset{\cdot}{x_{2}}=(\theta-t)(u_{2}+v_{2}) \end{array}\end{displaymath}](img163.gif)
![$\displaystyle \sigma_{i}(x[\theta])=-\left\Vert x[\theta]-a^{(i)}\right\Vert ,\quad x=(x_{1} ,x_{2}),\ \ i=1,2$](img164.gif)